Python3.6 scikit-learn(1)1. 机器学习方法的分类监督学习无监督学习半监督学习强化学习遗传算法2. scikit-learn2.1 sklearn中的通用学习模式 sklearn 中有自带的数据库,可以通过导入模块的数据库来进行训练学习...
”sklearn 数据集 python3.6“ 的搜索结果
今天小编就为大家分享一篇对sklearn的使用之数据集的拆分与训练详解(python3.6),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
为了后期环境配置,我们选择安装对应版本的anaconda,python3.6对应的anaconda版本为3-5.0.1,进入官网或者清华大学镜像网站去下载对应版本。点进去看发现这不就是一个python安装过后的文件吗,说是创建虚拟环境,...
模型报告以及几个重要问题:①标签二值化②网格搜索法调参③k折交叉验证④增加噪声特征(之前涉及)from sklearn import datasets#从cross_validation导入会出现warning,说已弃用from sklearn.model_selection import...
train_test_split()函数:交叉验证一般形式:如下,from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(train_data,train_target,test_size=0.4,test_size=...

机器学习入门-sklearn
模型报告以及几个重要问题:①标签二值化②网格搜索法调参③k折交叉验证④增加噪声特征(之前涉及)from sklearn import datasets#从cross_validation导入会出现warning,说已弃用from sklearn.model_selection import...
鸢尾花(Iris)数据集,是机器学习和统计学中一个经典的数据集。它包含在 scikit-learn 的 datasets 模块中。
文章目录KNN分类算法原理新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建...

模型报告以及几个重要问题:①标签二值化②网格搜索法调参③k折交叉验证④增加噪声特征(之前涉及)from sklearn import datasets#从cross_validation导入会出现warning,说已弃用from sklearn.model_selection import...
RandomForest 随机森林 在上一篇博文 “集成算法— 简介 + 决策树”中,简要介绍了集成算法的3种分类:Boosting、Bagging、Stacking以及它们经常使用的弱分类器—决策树(分类树和回归树)。集成算法可分为序列集成...
通过上面的描述信息,我们可以知道该数据集包含150条数据,每50条数据属于一个类别,即有三个类别,每一条数据有四个特征。target_names 键对应的值是一个字符串数组,里面包含我们要预测的花的品种: 输出: 由此,...
研修课上讲了两个例子,融合一下。 主要演示大致的过程: 导入->拆分->训练->模型报告 以及几个重要问题: ...from sklearn import datasets ...from sklearn.model_select...
python 3.6 simple_classification.py 机器学习简单分类例子,用训练数据拟合分类器模型,用训练好的分类器去预测数据集的标签, 带注释帮助理解 。
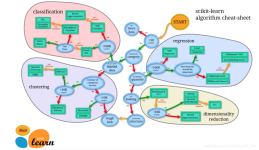
scikit-learn数据集API介绍 sklearn小数据集 sklearn.datasets.load_iris() sklearn.datasets.load_boston() sklearn大数据集
在Python 3.6中,我们可以使用以下代码来加载数据集、预处理文本、提取特征并训练分类器: ``` import nltk from nltk.corpus import stopwords from sklearn.feature_extraction.text import TfidfVectorizer from...
本文带你一探鸢尾花数据集的奥秘,基于sklearn轻松加载,掌握数据集加载技巧。 通过探索数据集特征,你将深入理解机器学习基础。更有模型训练实战,让你从零到一构建分类器。 模型性能不佳?别担心,我们教你如何...

鸢尾花(Iris)数据集,是机器学习和统计学中一个经典的数据集。它包含在 scikit-learn 的 datasets 模块中。我们可以调用 load_iris 函数来加载数据: load_iris 返回的 iris 对象是一个 Bunch 对象,与字典非常...
注意,最后一个是json文件,里面是电影影评数据集MR的划分出来的训练集生成的词典。是个字典文件,也可以自己再弄一个。 在训练集上训练了10个epoch,结果大概是上图这个样子 1、创建model_para.py文件,里面是模型...
整理今天的代码……采用的是150条鸢尾花的数据集fishiris.csv# 读入数据,把Name列取出来作为标签(groundtruth)import pandas as pddata = pd.read_csv('fishiris.csv')print(data.head(5))X = data.iloc[:, data....
本文介绍了如何加载各种数据源,以生成可以用于sklearn使用的数据集。主要包括以下几类数据源: 预定义的公共数据源 内存中的数据 csv文件 任意格式的数据文件 稀疏数据格式文件 sklearn使用的数据集一般为numpy ...

sklearn数据集 1、数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型(分类、回归和聚类) 测试数据:在模型检验时使用,用于评估模型是否有效 划分的时候一般就是75%和25%的比例。 ...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地